
做SSRF测试的时候,常提到用类似 a 字符来bypass过滤器,之前没有做深究,偶然的一次机会,发现baidu.com(\uff41)能跳转到百度,但是bаidu.com(\u0430)会被认为是一个新的IDN域名,并不指向baidu.com。
先在浏览器中打开工具调试,发现第一个case在HTTP包中的Host字段的值是baidu.com,那么应该是先处理过再发送的请求。
想到了其中可能会有编码转换,简单看了一下IDN的RFC没有找到有价值的信息,于是开始找源码,以idna为关键字在WebKit的源码中找到相关函数 uidna_nameToUnicode ,在Chromium中也找到这个函数。
顺着关键字找到icu标准的实现,其在官方网站上很清楚的给出了转换的demo和浏览器normalize的demo,那么使用其进行测试。
baidu.com测试结果入下:
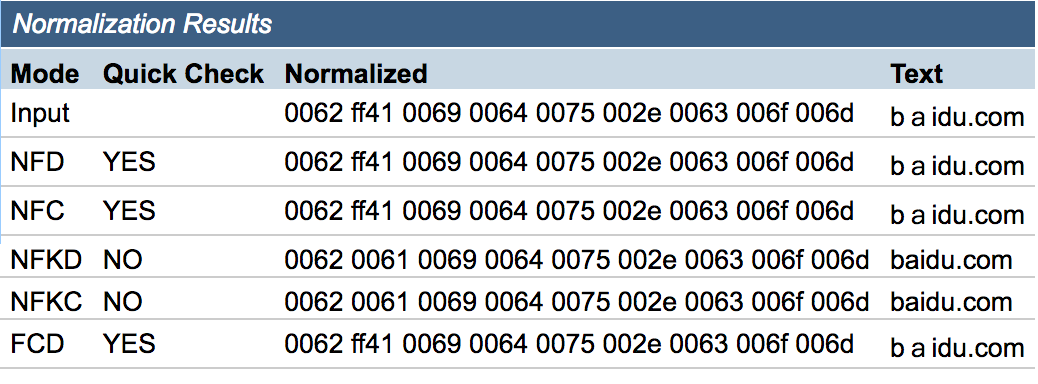
bаidu.com测试结果入下:
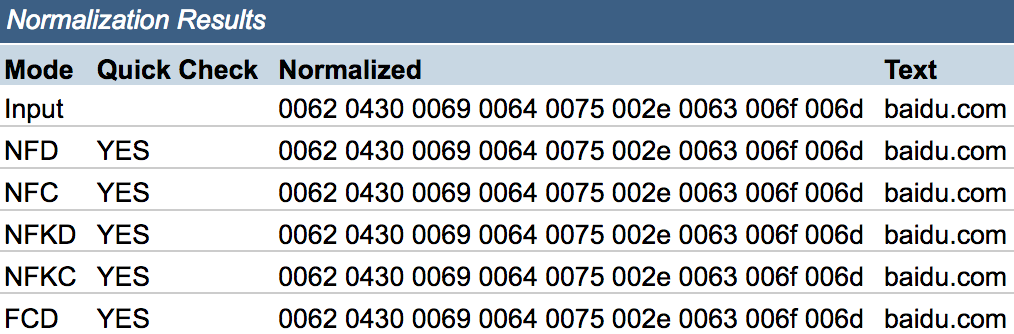
从上面这个结果可以看到\uff41在某些模式下会被转换,而\u0430在所有模式下都不会被转换,那么到这里这个问题已经有一个初步的答案了,第一个case被normalize转换为ascii,所以能正常解析。第二个case不会被转换,被做为unicode处理,所以会访问IDN域名。
但是这个答案还不够清晰,于是继续顺着线索找到unicode转换的标准。标准中提到,两个不同编码的Unicode字符可能存在一定的等价性,这种等价是字符或字符序列之间比较弱的等价类型,这些变体形式可能代表在某些字体或语境中存在视觉上或意义上的相似性。举例来说,a 和a(\uff41)在某些字体下看起来可能相同,15和⑮(\u246e)其表示的数学意义可能相同,所以这两种字符都有其相应的等价性,这种等价性是由人为规定的。更具体的说明可以参考wiki。
转换组成字符的方式有 Normalization Form C 和 Normalization Form KC 两种,它们之间的区别取决于生成的文本是否与原始非标准化文本等效,其中K用于表示兼容性。同理,分解组成字符的方式也有Normalization Form D 和 Normalization Form KD 两种。那么NFC和NFD的区别是什么呢,举例来说,Å(\u212B)用NFD进行normalize,会变为Å(\u0041\u030a),而NFC处理后则是Å(\u00c5)。在normalize的时候,会检测字符是否在NFC表中,如果在则进行对应的转换算法。回到之前的问题,\uff41会被normalize,而\u0430不被normalize,在请求时因为其中包含unicode字符,所以会被认为是IDN域名。
到此为止,开头的问题已经基本清楚了。在接下来,想构造字符对应的等效码表,来为平时的测试服务。以简单考虑,这里不对icu的代码做深究,一个简单的想法是,对所有字符遍历一次,寻找normalize后相等的字符即可。那么一个简单的获取可打印ascii字符的等效字符的脚本如下:
1 | #!/usr/bin/env python |